
-
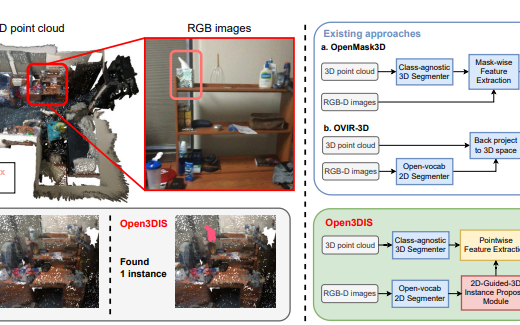 Open3DIS: Open-Vocabulary 3D Instance Segmentation with 2D Mask Guidance
Open3DIS: Open-Vocabulary 3D Instance Segmentation with 2D Mask GuidancePublication: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern …, 2024 . We introduce Open3DIS, a novel solution designed to tackle the problem of Open-Vocabulary Instance Segmentation within 3D scenes. Objects within 3D environments exhibit diverse shapes, scales, and colors, making precise instance-level identification a challenging task. Recent advancements in Open-Vocabulary scene understanding have made significant strides in this area by employing classagnostic 3D instance proposal networks for object localization and learning queryable features for each 3D mask. While these methods produce high-quality instance proposals, they struggle with identifying small-scale and geometrically ambiguous objects. The key idea of our method is a new module that aggregates 2D instance masks across frames and maps them to geometrically coherent point cloud regions as high-quality object proposals addressing the above limitations. These are then combined with 3D class-agnostic instance proposals to include a wide range of objects in the real world. To validate our approach, we conducted experiments on three prominent datasets, including ScanNet200, S3DIS, and Replica, demonstrating significant performance gains in segmenting objects with diverse categories over the state-of-the-art approaches.
-
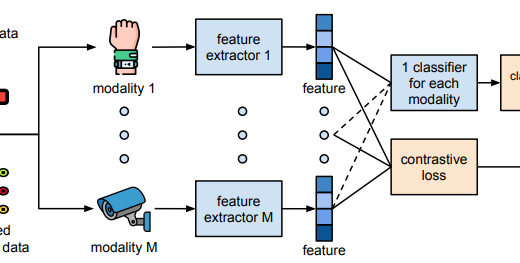 Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
Virtual Fusion with Contrastive Learning for Single Sensor-based Activity RecognitionPublication: IEEE Sensors Journal, 2024. Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user’s motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.
-
 FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image Editing
FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image EditingPublication: arXiv preprint arXiv:2403.18605, 2024. Our work addresses limitations seen in previous approaches for object-centric editing problems, such as unrealistic results due to shape discrepancies and limited control in object replacement or insertion. To this end, we introduce FlexEdit, a flexible and controllable editing framework for objects where we iteratively adjust latents at each denoising step using our FlexEdit block. Initially, we optimize latents at test time to align with specified object constraints. Then, our framework employs an adaptive mask, automatically extracted during denoising, to protect the background while seamlessly blending new content into the target image. We demonstrate the versatility of FlexEdit in various object editing tasks and curate an evaluation test suite with samples from both real and synthetic images, along with novel evaluation metrics designed for object-centric editing. We conduct extensive experiments on different editing scenarios, demonstrating the superiority of our editing framework over recent advanced text-guided image editing methods. Our project page is published at https://flex-edit.github.io/.
-
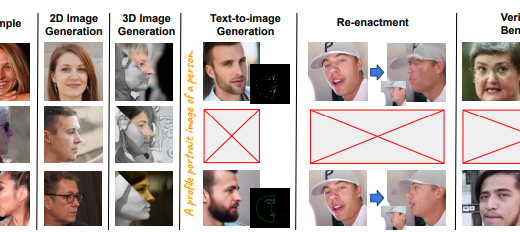 EFHQ: Multi-purpose ExtremePose-Face-HQ dataset
EFHQ: Multi-purpose ExtremePose-Face-HQ datasetPublication: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern …, 2024. The existing facial datasets, while having plentiful images at near frontal views, lack images with extreme head poses, leading to the downgraded performance of deep learning models when dealing with profile or pitched faces. This work aims to address this gap by introducing a novel dataset named Extreme Pose Face High-Quality Dataset (EFHQ), which includes a maximum of 450k highquality images of faces at extreme poses. To produce such a massive dataset, we utilize a novel and meticulous dataset processing pipeline to curate two publicly available datasets, VFHQ and CelebV-HQ, which contain many high-resolution face videos captured in various settings. Our dataset can complement existing datasets on various facial-related tasks, such as facial synthesis with 2D/3Daware GAN, diffusion-based text-to-image face generation, and face reenactment. Specifically, training with EFHQ helps models generalize well across diverse poses, significantly improving performance in scenarios involving extreme views, confirmed by extensive experiments. Additionally, we utilize EFHQ to define a challenging cross-view face verification benchmark, in which the performance of SOTA face recognition models drops 5-37% compared to frontal-to-frontal scenarios, aiming to stimulate studies on face recognition under severe pose conditions in the wild.
-
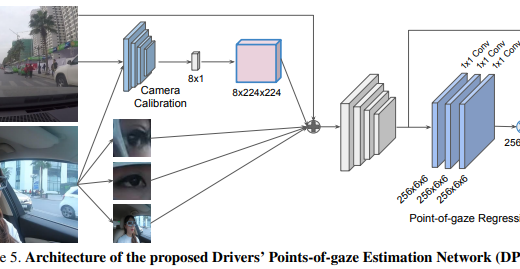 Driver Attention Tracking and Analysis
Driver Attention Tracking and AnalysisPublication: arXiv preprint arXiv:2404.07122, 2024. We propose a novel method to estimate a driver’s pointsof-gaze using a pair of ordinary cameras mounted on the windshield and dashboard of a car. This is a challenging problem due to the dynamics of traffic environments with 3D scenes of unknown depths. This problem is further complicated by the volatile distance between the driver and the camera system. To tackle these challenges, we develop a novel convolutional network that simultaneously analyzes the image of the scene and the image of the driver’s face. This network has a camera calibration module that can compute an embedding vector that represents the spatial configuration between the driver and the camera system. This calibration module improves the overall network’s performance, which can be jointly trained end to end. We also address the lack of annotated data for training and evaluation by introducing a large-scale driving dataset with point-of-gaze annotations. This is an in situ dataset of real driving sessions in an urban city, containing synchronized images of the driving scene as well as the face and gaze of the driver. Experiments on this dataset show that the proposed method outperforms various baseline methods, having the mean prediction error of 29.69 pixels, which is relatively small compared to the 1280×720 resolution of the scene camera.
-
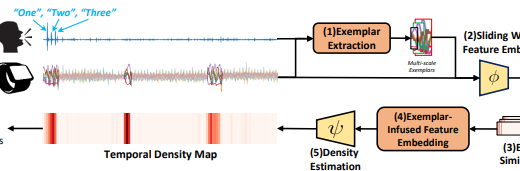 Count What You Want: Exemplar Identification and Few-shot Counting of Human Actions in the Wild
Count What You Want: Exemplar Identification and Few-shot Counting of Human Actions in the WildPublication: Proceedings of the AAAI Conference on Artificial Intelligence 38 (9), 10057 …, 2024. This paper addresses the task of counting human actions of interest using sensor data from wearable devices. We propose a novel exemplar-based framework, allowing users to provide exemplars of the actions they want to count by vocalizing predefined sounds “one”, “two”, and “three”. Our method first localizes temporal positions of these utterances from the audio sequence. These positions serve as the basis for identifying exemplars representing the action class of interest. A similarity map is then computed between the exemplars and the entire sensor data sequence, which is further fed into a density estimation module to generate a sequence of estimated density values. Summing these density values provides the final count. To develop and evaluate our approach, we introduce a diverse and realistic dataset consisting of real-world data from 37 subjects and 50 action categories, encompassing both sensor and audio data. The experiments on this dataset demonstrate the viability of the proposed method in counting instances of actions from new classes and subjects that were not part of the training data. On average, the discrepancy between the predicted count and the ground truth value is 7.47, significantly lower than the errors of the frequency-based and transformer-based methods. Our project, code and dataset can be found at https://github.com/cvlab-stonybrook/ExRAC.
-
 OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene UnderstandingPublication: arXiv preprint arXiv:2402.15321, 2024 . This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. Additional details are available on the OpenSUN3D workshop website.
-
 Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown Domains
Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown DomainsPublication: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern …, 2024. This paper presents an innovative framework designed to train an image deblurring algorithm tailored to a specific camera device. This algorithm works by transforming a blurry input image, which is challenging to deblur, into another blurry image that is more amenable to deblurring. The transformation process, from one blurry state to another, leverages unpaired data consisting of sharp and blurry images captured by the target camera device. Learning this blur-to-blur transformation is inherently simpler than direct blur-to-sharp conversion, as it primarily involves modifying blur patterns rather than the intricate task of reconstructing fine image details. The efficacy of the proposed approach has been demonstrated through comprehensive experiments on various benchmarks, where it significantly outperforms state-of-the-art methods both quantitatively and qualitatively. Our code and data are available at https://zero1778.github.io/blur2blur/
-
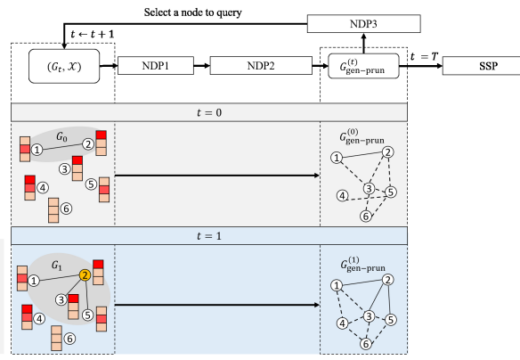 IM-META: Influence Maximization Using Node Metadata in Networks With Unknown Topology
IM-META: Influence Maximization Using Node Metadata in Networks With Unknown TopologyPublication: IEEE Transactions on Network Science and Engineering, 2024 . Since the structure of complex networks is often unknown, we may identify the most influential seed nodes by exploring only a part of the underlying network, given a small budget for node queries. We propose IM-META, a solution to influence maximization (IM) in networks with unknown topology by retrieving information from queries and node metadata. Since using such metadata is not without risk due to the noisy nature of metadata and uncertainties in connectivity inference, we formulate a new IM problem that aims to find both seed nodes and queried nodes. In IM-META, we develop an effective method that iteratively performs three steps: 1) we learn the relationship between collected metadata and edges via a Siamese neural network, 2) we select a number of inferred confident edges to construct a reinforced graph, and 3) we identify the next node to query by maximizing the inferred influence spread using our topology-aware ranking strategy. Through experimental evaluation of IM-META on four real-world datasets, we demonstrate a) the speed of network exploration via node queries, b) the effectiveness of each module, c) the superiority over benchmark methods, d) the robustness to more difficult settings, e) the hyperparameter sensitivity, and f) the scalability
-
 On the Combination of Multi-Input and Self-Attention for Sign Language Recognition
On the Combination of Multi-Input and Self-Attention for Sign Language RecognitionPublication: International Journal of Advanced Computer Science & Applications 15 (4), 2024. Sign language recognition can be considered as a branch of human action recognition. The deaf-muted community utilizes upper body gestures to convey sign language words. With the rapid development of intelligent systems based on deep learning models, video-based sign language recognition models can be integrated into services and products to improve the quality of life for the deaf-muted community. However, comprehending the relationship between different words within videos is a complex and challenging task, particularly in understanding sign language actions in videos, further constraining the performance of previous methods. Recent methods have been explored to generate video annotations to address this challenge, such as creating questions and answers for images. An optimistic approach involves fine-tuning autoregressive language models trained using multiinput and self-attention mechanisms to facilitate understanding of sign language in videos. We have introduced a bidirectional transformer language model, MISA (multi-input self-attention), to enhance solutions for VideoQA (video question and answer) without relying on labeled annotations. Specifically, (1) one direction of the model generates descriptions for each frame of the video to learn from the frames and their descriptions, and (2) the other direction generates questions for each frame of the video, then integrates inference with the first aspect to produce questions that effectively identify sign language actions. Our proposed method has outperformed recent techniques in VideoQA by eliminating the need for manual labeling across various datasets, including CSL-Daily, PHOENIX14T, and PVSL (our dataset). Furthermore, it demonstrates competitive performance in lowdata environments and operates under supervision.